目录
1 泛型编程
2 函数模板
3 类模板
1 泛型编程
模板是泛型编程的基础,泛型我们碰到过多次了,比如malloc函数返回的就是泛型指针,需要我们强转。
既然是泛型编程,也就是说我们可以通过一个样例来解决类似的问题,比如:
void swap(int& a,int& b)
{
int tmp = a;
a = b;
b = tmp;
}
就交换问题来说,我们可以交换整型,可以交换浮点型,但是我们可不可以在一个文件里面实现同时交换两种类型呢?实际上对于C语言来说是不可以的,因为C语言没有模板的概念。
可能会说用typedef ,但是用了也只能解决交换其他类型的原因,不能实现同时交换两种不同的类型,也可能说用auto,但是auto不能作为函数参数使用。
这里就需要用到模板了,模板使用到了两个关键字,一个是template ,一个是typename,template是模板的英文名,typename是类型名的英文,还是很好理解的。
使用如下:
template <typename T1, typename T2,…… typename Tn>
2 函数模板
相关的关键字只有两个,这里来谈一下使用的问题,具体使用如下:
template <typename T>
//模板
void Swap(T& a,T& b)
{
T tmp = a;
a = b;
b = tmp;
}
int main()
{
int a = 1, b = 2;
Swap(a, b);
double c = 1.1, d = 2.2;
Swap(c, d);
return 0;
}可能看起来比较抽象?
模板实现的原理是模板实例化,背后靠的都是编译器,编译器会自动推演需要的类型,所以这里会有一个问题:两次交换调用的是同一个函数吗?
当然不是的,这里可以借助汇编看一下:

汇编层面可以看到调用的函数的地址不一样,所以调用的函数不是一个函数。
模板其实是编译器在负重前面,我们使用模板的时候,编译器自动推演出我们需要的函数,
那么这里就涉及效率问题了,某种意义上来说模板的调用效率确实没有直接调用来的快,但是省事儿,我们不用再去多写那么多行代码了,毕竟函数重载也要多写代码的
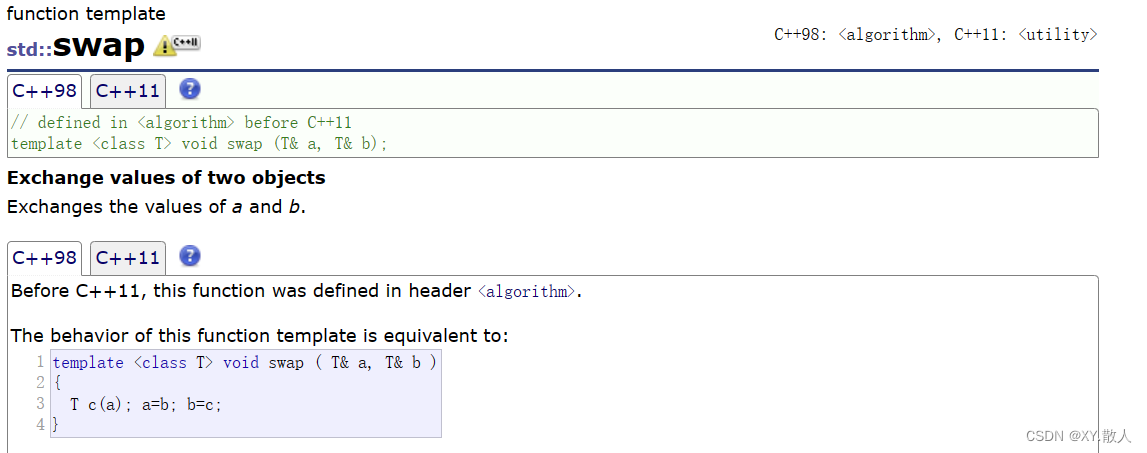
基本的使用我们了解了,以后我们使用交换函数也不用自己去实现了,因为库里面有,可以直接进行使用:
现在有一些问题:
使用模板的时候,我们想要交换类型不同的怎么办?
如果我们尝试直接交换a c的话,就会报错,即没有函数模板是可以使用的

为了方便演示使用加法函数:
T Add(T x,T y)
{
return x + y;
}解决方法1->强制转换:
int main()
{
int a = 1;
double b = 2.5;
Add(a,(int)b);
return 0;
}
但是这种处理方法丢失了原本我们期待的结果,它造成了精度的丢失。
解决方法2->显式实例化:
int main()
{
int a = 1;
double b = 2.5;
double ret = Add<double>(a,b);
cout << ret;
return 0;
}int main()
{
int a = 1;
double b = 2.5;
cout << Add<int,double>(a, b) << endl;
return 0;
}显式实例化可以让编译器不去自动推演参数类型。
我们知道最后的结果是double类型的,所以显式调用double类型的加法函数,调用的写法是函数后面加个<>,里面写要显式调用的类型,但是呢,都差点意思。
解决方法3->多个模板混用 + auto:
template <typename T1,typename T2>
auto Add(const T1& x,const T2& y)
{
return x + y;
}
int main()
{
int a = 1;
double b = 2.5;
cout << Add(a, b) << endl;
return 0;
}既然是多参数,那么我们使用不同的模板就行,但是返回值的话,就用auto即可,这里可以说auto很妙,不会存在丢失精度的问题,也不用显式实例化,也不用强转什么的。
但是有些情况,是必须要显式实例化的:
T* Func(int a)
{
T* p = (T*)operator new(sizeof(T));
new(p)T(a);
return p;
}返回的是一个指针,但是函数返回什么类型呢?如果没有显式实例化的话是没有办法返回的。
这里就必须要显式实例化了:
int main()
{
int a = 1;
Func<int>(a);
return 0;
}再补充一个小点,typename可以用class进行代替,二者完全等价的。
template <typename T>
template <class T>
两种写法均可。
这里在引入一个点,叫匹配原则,有合适的优先选择合适的:
//整型的加法函数
int Add(int x,int y)
{
cout << "int Add(int x,int y)" << endl;
return x + y;
}
//通用加法函数
template <typename T1,typename T2>
auto Add(const T1& a,const T2& b)
{
cout << "auto Add(const T1& a,const T2& b)" << endl;
return a + b;
}
//一般加法
template<typename T>
T Add(const T& left, const T& right)
{
cout << "T Add(const T& left, const T& right)" << endl;
return left + right;
}这里提供了三个函数可以实现加法,一个是类型完全匹配的,一个是通用的加法函数,一个是需要编译器需要自己推演的:
int main()
{
cout << Add(1, 3) << endl;
cout << Add(1, 3.3) << endl;
cout << Add(1.1, 3.1) << endl;
return 0;
}那么这里的调用,就会:
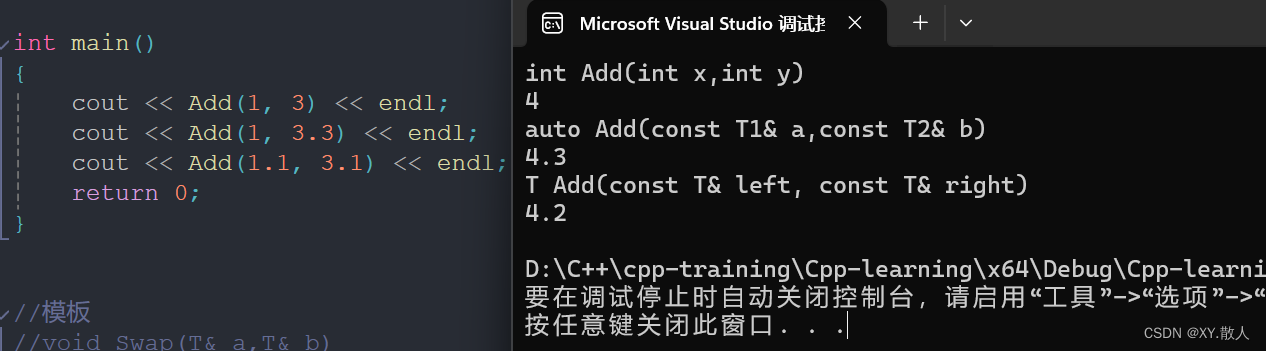
第一个,因为完全匹配非模板的函数,所以优先调用;
第二个,因为更匹配通用的加法函数,需要编译器自己推演的力度没有那么大,所以调用两个模板的参数。
第三个,完全需要编译器自己推理,那就只能它了。
所以函数模板的调用也要看谁更匹配,优先使用更匹配的,编译器也想休息~
3 类模板
类模板其实后面用的最多的,现在先做个了解,比如stack,我们要实现两种栈,一个是用来存储int数据,一个是用来存储数据double的,就需要用到模板,不然解决不了一个文件存在两个类型栈的情况:
template<typename T>
class Stack
{
public:
Stack(size_t capacity = 4)
{
_array = (T*)malloc(sizeof(T) * capacity);
if (nullptr == _array)
{
perror("malloc申请空间失败");
return;
}
_capacity = capacity;
_size = 0;
}
void Push(const T& data);
private:
T* _array;
size_t _capacity;
size_t _size;
};有了模板之后,我们实现相同的就很容易了,这里如果里面的函数定义和声明分离的话,如果不是同一个.h文件的话,造成的效果是很难想象的,会造成编译的时间大幅度的增加。
分离之后的写法:
template<typename T>
class Stack
{
public:
Stack(size_t capacity = 4)
{
_array = (T*)malloc(sizeof(T) * capacity);
if (nullptr == _array)
{
perror("malloc申请空间失败");
return;
}
_capacity = capacity;
_size = 0;
}
void Push(const T& data);
private:
T* _array;
size_t _capacity;
size_t _size;
};
template<class T>
void Stack<T>::Push(const T& data)
{
;
}
创建不同的Stack就显式实例化就可以了:
int main()
{
stack<int> p1;
stack<double> p2;
return 0;
}模板初阶还是好理解的,后面介绍高阶的。
感谢阅读!


![60、郑州大学附属肿瘤医院 :用于预测胃癌患者术后生存的深度学习模型的开发和验证[同学,我们的人生应当是旷野]](https://img-blog.csdnimg.cn/direct/ea8f3a8652894ce0b929d195d0994d65.png)